
[Note: Many of the medical and scientific terms used in this summary are found in the NCI Dictionary of Genetics Terms. When a linked term is clicked, the definition will appear in a separate window.]
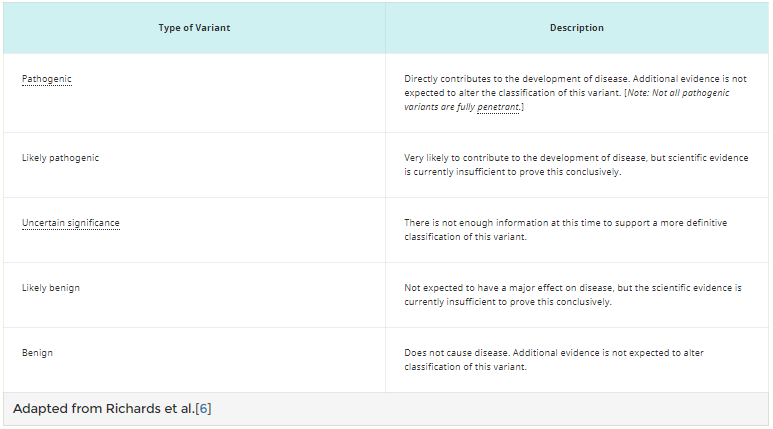
[Note: A concerted effort is being made within the genetics community to shift terminology used to describe genetic variation. The shift is to use the term “variant” rather than the term “mutation” to describe a difference that exists between the person or group being studied and the reference sequence, particularly for differences that exist in the germline. Variants can then be further classified as benign (harmless), likely benign, of uncertain significance, likely pathogenic, or pathogenic (disease causing). Throughout this summary, we will use the term pathogenic variant to describe a disease-causing mutation. Refer to Table 1, Variant Classification for Pathogenicity for more information.]
The etiology of cancer is multifactorial, with genetic, environmental, medical, and lifestyle factors interacting to produce a given malignancy. Knowledge of cancer genetics is rapidly improving our understanding of cancer biology, helping to identify at-risk individuals, furthering the ability to characterize malignancies, establishing treatment tailored to the molecular fingerprint of the disease, and leading to the development of new therapeutic modalities. As a consequence, this expanding knowledge base has implications for all aspects of cancer management, including prevention, screening, and treatment.
Genetic information provides a means of identifying people who have an increased risk of cancer. Sources of genetic information include biologic samples of DNA, information derived from a person’s family history of disease, findings from physical examinations, and medical records. DNA-based information can be gathered, stored, and analyzed at any time during an individual’s life span, from before conception to after death. Family history may identify people with a modest to moderately increased risk of cancer or may serve as the first step in the identification of an inherited cancer predisposition that confers a very high lifetime risk of cancer. For an increasing number of diseases, DNA-based testing can be used to identify a specific pathogenic variant as the cause of inherited risk and to determine whether family members have inherited the disease-related variant.
The proportion of individuals carrying a pathogenic variant who will manifest the disease is referred to as penetrance. In general, common genetic variants that are associated with cancer susceptibility have a lower penetrance than rare genetic variants. This is depicted in Figure 1. For adult-onset diseases, penetrance is usually described by the individual carrier’s age and sex. For example, the penetrance for breast cancer in female carriers of BRCA1/BRCA2 pathogenic variants is often quoted by age 50 years and by age 70 years. Of the numerous methods for estimating penetrance, none are without potential biases, and determining an individual carrier’s risk of cancer involves some level of imprecision.
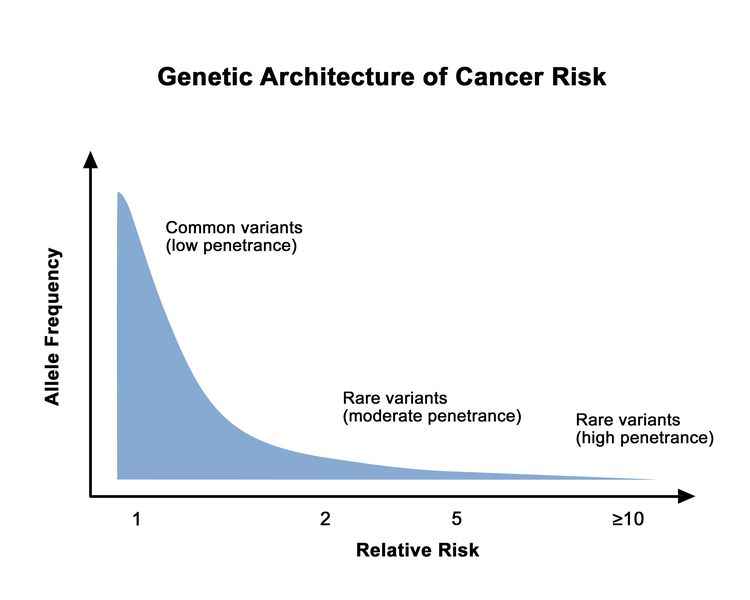
Genetic variants, or changes in the usual DNA sequence of a particular gene, can have harmful, beneficial, neutral, or uncertain effects on health and may be inherited as autosomal dominant, autosomal recessive, or X-linked traits. Pathogenic variants that cause serious disability early in life are usually rare because of their adverse effect on life expectancy and reproduction. However, if the pathogenic variant is autosomal recessive—that is, if the health effect of the variant is caused only when two copies (one from each parent) of the altered gene are inherited— carriers of the pathogenic variant (healthy people carrying one copy of the altered gene) may be relatively common in the general population. Common in this context refers, by convention, to a prevalence of 1% or more. Pathogenic variants that cause health effects in middle and older age, including several pathogenic variants known to cause a predisposition to cancer, may also be relatively common. Many cancer-predisposing traits are inherited in an autosomal dominant fashion, that is, the cancer susceptibility occurs when only one copy of the altered gene is inherited. For autosomal dominant conditions, the term carrier is often used in a less formal manner to denote people who have inherited the genetic predisposition conferred by the pathogenic variant. (Refer to individual PDQ summaries focused on the genetics of specific cancers for detailed information on known cancer-susceptibility syndromes.)
Increasingly, the public is turning to the Internet for information related both to familial and genetic susceptibility to cancer and to genetic risk assessment and testing. Direct-to-consumer marketing of genetic testing for hereditary breast and colon cancer is also taking place in some communities. This wider availability of information related to inherited cancer risk may raise concerns among persons previously unaware of the implications inherent in their family histories and may lead some of these individuals to consult their primary care physicians for management advice and recommendations. In many instances, the evaluation and advice will be relatively straightforward for physicians with a basic knowledge of familial cancer. In a subset of patients, the evaluation may be more complex, calling for referral to genetics professionals for further evaluation and counseling.
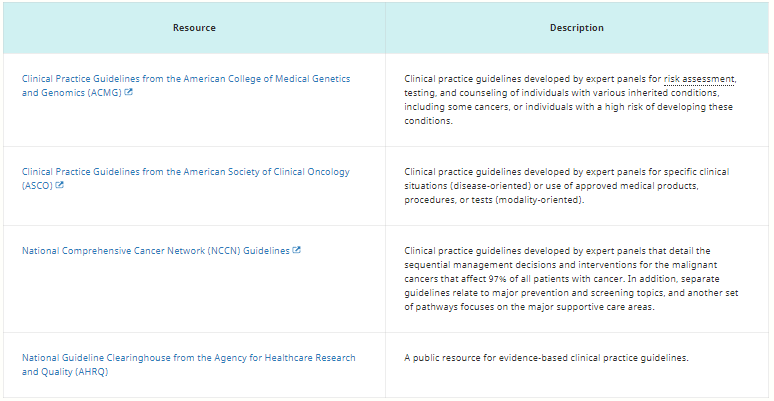
Correctly recognizing and identifying individuals and families at increased risk of developing cancer is one of countless important roles for primary care and other health care providers. Once identified, these individuals can then be appropriately referred for genetic counseling, risk assessment, consideration of genetic testing, and development of a management plan. When medical and family histories reveal cardinal clues to the presence of an underlying familial or genetic cancer susceptibility disorder (see list below),[1] further evaluation may be warranted. (Refer to the PDQ summary on Cancer Genetics Risk Assessment and Counseling for more information about the components of a genetics cancer risk assessment.)
Features of hereditary cancer include the following:
Concluding that an individual is at increased risk of developing cancer may have important, potentially life-saving management implications and may lead to specific interventions aimed at reducing risk (e.g., tamoxifen for breast cancer, colonoscopy for colon cancer, or risk-reducing salpingo-oophorectomy for ovarian cancer). Information about familial cancer risk may also inform a person’s ability to plan for the future (lifestyle and health care decisions, family planning, or other decisions). Genetic information may also provide a direct health benefit by demonstrating the lack of an inherited cancer susceptibility. For example, if a family is known to carry a cancer-predisposing variant in a particular gene, a family member may experience reduced worry and lower health care costs if his or her genetic test indicates that he or she does not carry the family’s disease-related variant. Conversely, information about familial cancer risk may have psychological effects or social costs (e.g., worry, guilt, or increased health care costs). Family dynamics also may be affected. For instance, the involvement of one or more family members may be required for genetic testing to be informative, and parents may feel guilt about passing inherited risk on to their children.
Knowledge about a cancer-predisposing variant can be informative not only for the individual tested but also for other family members. Family members who previously had not considered the implications of their family history for their own health may be led to do so, and some will undergo genetic testing, resulting in more definitive information on whether they are at increased genetic risk. Some relatives may learn their carrier status without being directly tested, for example, when a biological parent of a child who is a known carrier of a pathogenic variant is identified as an obligate carrier. Founder effects may result in the recognition that specific ethnic groups have a higher prevalence of certain pathogenic variants, knowledge that can be either clinically useful (permitting more rational genetic testing strategies) or potentially stigmatizing. Testing may reveal the presence of nonpaternity in a family. There is the theoretical possibility that genetic information may be misused, and concerns about the potential for insurance and/or employment discrimination may arise. Genetic information may also affect medical and lifestyle decisions.
Refer to individual PDQ summaries for available evidence addressing all ancillary issues.
References
Genetic counseling is a process of communication between genetics professionals and patients with the goal of providing individuals and families with information on the relevant aspects of their genetic health, available testing and management options, and support as they move toward understanding and incorporating this information into their daily lives. Genetic counseling generally involves the following six steps:
Genetic evaluation involves an interaction with a medical geneticist or other genetics professional and may include a physical examination and diagnostic testing, in addition to genetic counseling. The principles of voluntary and informed decision making, nondirective and noncoercive counseling, and protection of client confidentiality and privacy are central to the philosophy of genetic counseling.[1–5] (Refer to the PDQ summary on Cancer Genetics Risk Assessment and Counseling for more information on the nature and history of genetic counseling.)
From the mid-1990s to the mid-2000s, genetic counseling expanded to include discussion of genetic testing for cancer risk, as more genes associated with inherited cancer risk were discovered. Cancer genetic counseling often involves a multidisciplinary team of health professionals that may include a genetic counselor, an advanced practice genetics nurse, or a medical geneticist; a mental health professional; and various medical experts such as an oncologist, surgeon, or internist. The process of counseling may require a number of visits to address medical, genetic testing, and psychosocial issues. Even when cancer risk counseling is initiated by an individual, inherited cancer risk has implications for the entire family. Because genetic risk affects an unknown number of biological relatives, contact with these relatives is often essential to collect accurate family and medical histories. Cancer genetic counseling may involve several family members, some of whom will have had cancer and others who have not.
The impact of risk assessment and predisposition genetic testing is improved health outcomes. The information derived from risk assessment and/or genetic testing allows the health care provider to tailor an individual approach to health promotion and optimize long-term health outcomes through the identification of at-risk individuals before cancer develops. The health care provider can thus intervene earlier either to reduce the risk or diagnose a cancer at an earlier stage, when the chances for effective treatment are greatest. The information may be used to modify the management approach to an initial cancer, clarify the risks of other cancers, or predict the response of an existing cancer to specific forms of treatment, all of which may alter treatment recommendations and long-term follow-up.
References
Individual PDQ summaries focused on the genetics of specific cancers contain detailed information about many known cancer susceptibility syndromes. Although this is not a complete list, the following cancer susceptibility syndromes are discussed in the PDQ cancer genetics summaries (listed in parentheses after the syndromes):
The methods described in this section are intended to provide a brief background about the genetic analysis and discovery approaches that have been used during the past 10 to 15 years for identifying disease susceptibility genes. These methods led to important cancer gene discoveries such as BRCA1 and breast cancer risk. Since then, genetic analysis techniques have transitioned to next-generation sequencing methods as described in the Clinical Sequencing section of this summary.
The recognition that cancer clusters within families has led many investigators to collect data on multiple-case families with the goal of localizing cancer susceptibility genes through linkage studies.
Linkage studies are typically performed on high-risk kindreds, in whom multiple cases of a particular disease have occurred, in an effort to identify disease susceptibility genes. Linkage analysis statistically compares the genotypes between affected and unaffected individuals and looks for evidence that known genetic markers are inherited along with the disease trait. If such evidence is found (linkage), it provides statistical data that the chromosomal region near the marker also harbors a disease susceptibility gene. Once a genomic region of interest has been identified through linkage analysis, additional studies are required to prove that there truly is a susceptibility gene at that position. Linkage analysis is affected by the following:
An additional issue in linkage studies is the background rate of sporadic cancer in the context of family studies. For example, because a man’s lifetime risk of prostate cancer is one in eight,[1] it is possible that families under study have both inherited and sporadic prostate cancer cases. Thus, men who do not inherit the prostate cancer susceptibility gene that is segregating in their family may still develop prostate cancer.
One way to address inconsistencies between linkage studies is to require inclusion criteria that defines clinically significant disease.[2–6] This approach attempts to define a homogeneous set of cases/families to increase the likelihood of identifying a linkage signal. It also prevents the inclusion of cases that may be considered clinically insignificant that were identified by screening in families.
GWAS are identifying common, low-penetrance susceptibility alleles for many complex diseases,[7] including cancer. This approach can be contrasted with linkage analysis, which searches for genetic-risk variants cosegregating within families that have a high prevalence of disease. While linkage analyses are designed to uncover rare, highly penetrant variants that segregate in predictable heritance patterns (e.g., autosomal dominant, autosomal recessive, X-linked, and mitochondrial), GWAS are best suited to identify multiple, common, low-penetrance genetic polymorphisms. GWAS are conducted under the assumption that the genetic underpinnings of complex phenotypes, such as prostate cancer, are governed by many alleles, each conferring modest risk. Most genetic polymorphisms genotyped in GWAS are common, with minor allele frequencies greater than 1% to 5% within a given population (e.g., men of European ancestry). GWAS capture a large portion of common variation across the genome.[8,9] The strong correlation between many alleles located close to one another on a given chromosome (called linkage disequilibrium) allows one to “scan” the genome without having to test all 10 million known single nucleotide polymorphisms (SNPs). With GWAS, researchers can test approximately 1 million to 5 million SNPs per study and ascertain almost all common inherited variants in the genome.
In a GWAS, allele frequency for each SNP is compared between cases and controls. Promising signals—in which allele frequencies deviate significantly in case compared to control populations—are validated in replication cohorts. To have adequate statistical power to identify variants associated with a phenotype, large numbers of cases and controls, typically thousands of each, are studied. Because up to 1 million SNPs are evaluated in a GWAS, false-positive findings are expected to occur frequently when using standard statistical thresholds. Therefore, stringent statistical rules are used to declare a positive finding, usually using a threshold of P < 1 × 10-7.[10–12]
To date, hundreds of cancer-risk variants have been identified by well-powered GWAS and validated in independent cohorts.[13] These studies have revealed consistent associations between specific inherited variants and cancer risk. However, the findings should be qualified with a few important considerations:
The implications of these points are discussed in greater detail in the PDQ summaries on Genetics of Breast and Gynecologic Cancers; Genetics of Colorectal Cancer; and Genetics of Prostate Cancer. Additional details can be found elsewhere.[18]
References
Broad-scale genome sequencing approaches, including multigene (panel) testing, whole-exome sequencing (WES), and whole-genome sequencing (WGS), are rapidly being developed and incorporated into a spectrum of clinical oncologic settings, including cancer therapeutics and cancer risk assessment. Several institutions and companies offer tumor sequencing, and some are developing precision medicine programs that sequence tumor genomes to identify driver genetic alterations that are targetable for therapeutic benefit to patients.[1–3] Many of these tumor-based approaches use germline DNA sequences as a reference to discriminate between DNA changes only within the tumor and those that are potentially inherited. In the genetic counseling and cancer risk assessment setting, the use of multigene testing to evaluate inherited cancer risk is becoming more common and may become routine in the near future, with institutions and companies offering multigene testing to detect alterations in a host of cancer risk–associated genes.
These advances in gene sequencing technologies also identify variants in genes related to the primary indication for ordering genetic sequence testing, along with findings not related to the disorder being tested. The latter genetic findings, termed incidental or secondary findings, are currently a source of clinical, ethical, legal, and counseling debate. The American College of Medical Genetics and Genomics (ACMG) and the Presidential Commission for the Study of Bioethical Issues have published literature that address some of these issues and provide guidance and recommendations for their use.[4–7] However, controversy continues about when and what results to provide to patients and their health care providers. This section was created to provide information about genomic sequencing technologies in the context of clinical sequencing and highlights additional areas of clinical uncertainty for which further research and approaches are needed.
DNA sequencing technologies have undergone rapid evolution, particularly since 2005 when massively parallel sequencing, or next-generation sequencing (NGS), was introduced.[8]
Automated Sanger sequencing is considered the first generation of sequencing technology.[9] Sanger cancer gene sequencing uses polymerase chain reaction (PCR) amplification of genetic regions of interest followed by sequencing of PCR products using fluorescently labeled terminators, capillary electrophoresis separation of products, and laser signal detection of nucleotide sequence.[10,11] While this is an accurate sequencing technology, the main limitations of Sanger sequencing include low throughput, a limited ability to sequence more than a few genes at a time, and the inability to detect structural rearrangements.[10]
NGS refers to high throughput DNA sequencing technologies that are capable of processing multiple DNA sequences in parallel.[11] Although platforms differ in template generation and sequence interrogation, the overall approach to NGS technologies involves shearing and immobilizing DNA template molecules onto a solid surface, which allows separation of molecules for simultaneous sequencing reactions (millions to billions) to be performed in a parallel fashion.[10,12] Thus, the major advantages of NGS technologies include the ability to sequence thousands of genes at one time, a lower cost, and the ability to detect multiple types of genomic alterations, such as insertions, deletions, copy number alterations, and rearrangements.[10] Limitations include the possibility that specific gene regions may be missed, turnaround time can be lengthy (although it is decreasing), and informatics support to handle massive amounts of genetic data has lagged behind the sequencing capability. A well-recognized bottleneck to utilizing NGS data is the lack of advanced computational infrastructure to preserve, process, and analyze the vast amount of genetic data. The magnitude of the variants obtained from NGS is exponential; bioinformatics approaches need to evaluate genetic variants for predicted functional consequence in disease biology. There is also a need for user-friendly bioinformatics pipelines to analyze and integrate genetic data to influence the scientific and medical community.[11,13]
The following terms are defined to better understand the clinical application of NGS testing and implications of results reported.
NGS has multiple potential clinical applications. In oncology, the two dominant applications are: 1) the assessment of somatic alterations in tumors to inform prognosis and/or targeted therapeutics; and 2) the assessment of the germline to identify cancer risk alleles.
Somatic testing
There are multiple approaches to tumor testing for somatic alterations. With targeted multigene testing, a number of different genes can be assessed simultaneously. These targeted multigene tests can differ substantially in the genes that are included, and they can be tailored to individual tumor types. Targeted multigene testing limits the data to be analyzed and includes only known genes, which makes the interpretation more straightforward than in whole exome or whole genome techniques. In addition, greater depth of coverage is possible with targeted multigene testing than with WES or WGS. Depth of coverage refers to the number of times a nucleotide has been sequenced; a greater depth of coverage has fewer sequencing errors. Deep coverage also aids in differentiating sequencing errors from single nucleotide polymorphisms.
WES and WGS are far more extensive techniques and aim to uncover variants in known genes and in genes not suspected a priori. The discovery of a variant that is unexpected for a particular tumor type can lead to the use of a directed therapeutic, which could improve patient outcome. WES generates sequence data of the coding regions of the genome (representing approximately 1% of the human genome), rather than the entire genome (WGS). Consequently, WES is less expensive than WGS.
Noncoding variants can be identified using WGS but cannot be identified using WES. The use of WGS is limited by cost and the vast bioinformatics needed for interpretation. Although the costs of sequencing have dropped precipitously, the analysis remains formidable.[14]
Although the goal of WES and WGS is to improve patient care by detecting actionable genetic variants (mutations that can be targeted therapeutically), a number of issues warrant consideration. This testing may detect pathogenic variants, variants of uncertain significance (VUS), or no detectable abnormalities. In addition, pathogenic variants can be found in genes that are thought to be clearly related to tumorigenesis but can also be detected in genes with unclear relevance (particularly with WES and WGS approaches). VUS have unclear implications as they may, or may not, disrupt the function of the protein. The definition of actionable can vary, but often this term is used when an aberration, if found, would lead to recommendations against certain treatments (such as variants in ras) for which a clinical trial is available, or for which there is a known targeted drug. Although there are case reports of success with this approach, it is unlikely to be straightforward. Studies are ongoing.
Some commercial and single-institution assays test only the tumor. Clearly pathogenic variants found in important genes in the tumor can be somatic but could also be from the germline. In situations in which somatic analysis is paired with a germline analysis, it can be determined whether an identified alteration is inherited. A study that estimated the prevalence of germline variants from patients undergoing tumor sequencing with matched, normal DNA sequencing reported that cancer susceptibility genes were identified in 198 of 1,566 individuals (12.6%). Only 81 of these 198 individuals (40.9%) had pathogenic variants in cancer susceptibility genes concordant with their tumor type. When expanding to include known noncancer-related Mendelian disease genes, 246 of 1,566 individuals (15.7%) had pathogenic or presumed pathogenic germline variants identified.[15]
Sequencing tumors may lead to the identification of hereditary (germline) pathogenic variants.[16] Founder pathogenic variants in well-characterized cancer susceptibility genes are highly suggestive of a germline pathogenic variant. Hypermutated tumor phenotype may suggest an underlying constitutional defect in DNA repair. Clinical characteristics that fit with a particular genetic predisposition, such as family history, young age at diagnosis, or specific tumor type, may also raise the suspicion of a germline variant correlating with a tumor variant. A high variant allele fraction may also indicate a germline variant. All of these factors signify a potential need for patients to undergo genetic counseling and to consider confirmatory germline genetic testing.
The absence of a variant in a gene assessed as part of somatic testing does not rule out the presence of an inherited susceptibility. All patients whose personal and family histories are suggestive of hereditary cancer should consider germline testing regardless of their somatic results.
Ongoing clinical trials, such as the NCI Molecular Analysis for Therapy Choice (NCI-MATCH) Trial, are examining the value of somatic sequencing to find actionable targets. Germline sequencing is occurring as a component of this study.
Germline testing
The goal of germline testing is to identify pathogenic variants associated with an inherited risk of cancer and to guide cancer risk–management decisions. Also, germline testing can aid in some management decisions at the time of diagnosis (e.g., decisions about colectomy in Lynch syndrome–related colon cancer and contralateral mastectomy in carriers of BRCA1/BRCA2 pathogenic variants). In addition, there are emerging data that germline status may help determine systemic therapy (e.g., the use of cisplatin or poly [ADP-ribose] polymerase [PARP] inhibitors in BRCA1/BRCA2-related cancer).
To date, most germline genetic testing has been performed in a targeted manner, looking for variants in the gene(s) associated with a clinical picture (e.g., BRCA1 and BRCA2 in hereditary breast and ovarian cancer; or the mismatch repair [MMR] genes in Lynch syndrome). However, targeted multigene tests now available commercially or within an institution contain different sets of genes. Some are targeted to all cancers, others to specific cancers (e.g., breast, colon, or prostate cancers). The genes on the multigene tests include high-penetrance genes related to the specific tumor (such as BRCA1/BRCA2 on a breast cancer panel); high penetrance genes related to a different type of cancer but with a more moderate risk for the tumor of reference (such as CDH1 or MSH6 on a breast cancer panel); and moderate penetrance genes for which clinical utility is uncertain (such as NBN on a breast cancer panel). Because multiple genes are included on these panels, it is anticipated that many, and perhaps most, individuals undergoing testing using these panels will be found to have at least one VUS. As it is not possible to do standard pretest counseling models for a panel of 20 genes, new counseling models are needed. Ethical issues of whether patients can opt out of specific results (such as TP53 or CDH1 in breast cancer) and how this would be done in clinical practice are unresolved.
Refer to the Multigene (panel) testing section in the PDQ summary on Cancer Genetics Risk Assessment and Counseling for more information about the use of targeted multigene tests.
WES for inherited cancer susceptibility is also commercially available. Secondary findings are likely and management of such findings is evolving
The ACCE model uses four main components to evaluate new genetic tests: analytic validity; clinical validity; clinical utility; and ethical, legal, and social issues.[17]
The ACCE model’s framework has been adopted worldwide for the evaluation of genetic tests.
Several layers of complexity exist in managing NGS in the clinical setting. At the purely technical level, improvements in the sequencing technique have allowed for sequencing across the entire genome, not merely the exome. As the costs decrease, exomic and genomic sequencing of tumor and normal tissue can be expected to become more routine.
With routine use of WGS, major challenges in interpretation emerge. Foremost is the matter of determining which sequence variations in known cancer predisposition genes are pathologic, which are harmless, and which variations require further evaluation as to their significance. This is not a new challenge. Various groups are developing processes for the interpretation and curation of a growing database of variants and their significance. For example, the International Society for Gastrointestinal Hereditary Tumors has developed such a process for the MMR genes in concert with the Human Variome Project and International Mismatch Repair Consortium.
These processes may serve as a framework for the emerging challenge of interpreting the significance of sequence variations in genes of uncertain or unknown function in regulation of neoplastic progression or other diseases. Larger cancer predisposition multigene tests have been developed by commercial laboratories, with their own process for interpretation. To the extent that increasingly larger multigene tests include genes of unknown significance, governance of the interpretation process requires that academic institutions offering their own multigene tests or using external proprietary panels develop a deliberative process for managing the quality assurance for test performance (including Clinical Laboratory Improvement Amendments [CLIA], where appropriate) and interpretation.
ACMG has issued the following updated guidelines for achieving accountability in interpreting and reporting secondary findings:[4,18]
Concerns remain that the routine reporting of germline variants in the context of tumor sequencing would require laboratories to conduct results review with germline and tumor genome expertise, which would be expected to increase costs, laboratory efforts, and turnaround time for results reporting. The nature of discussions between oncologists and patients would be altered to include the multiple facets involved with germline testing and potential results. Pre- and post-test discussions would also potentially require involvement of genetic counselors and geneticists, who are a limited resource in oncology practices. Recent expert comment stated that more data are needed about the benefits of return of secondary germline findings to cancer patients undergoing tumor sequencing, citing a need for recommendations by experts in the oncology and genetics communities.[19]
It is still very early in the development processes for oversight at the institutional level. As an example, at one high-volume cancer center, the following process has been used:
Informed consent for the sequencing of highly penetrant disease genes has been conducted since the mid-1990s in the contexts of known or suspected inherited diseases within selected families. However, the best methods and approaches for educating and counseling individuals about the potential benefits, limitations, and harms of genetic testing to facilitate informed decisions have not been fully elucidated or adequately tested. New informed consent challenges arise as NGS technologies are applied in clinical and research settings. Challenges to facilitating informed consent include the following:
The increased availability and decreased cost of NGS technology are expanding the use of genome-wide testing of tumors, with the goal of identifying somatic mutations as potential targets for cancer treatment. While identifying germline pathogenic variants may be considered secondary to the main purpose of testing tumors, the possibility of identifying actionable secondary findings of pathogenic variants in cancer predisposition genes supports the need for genetic counseling in this context. Approaches for genetic counseling and informed consent in the context of tumor sequencing have been proposed.[20,21]
Advances in genetic sequencing technologies have dramatically reduced the cost of sequencing an individual’s full genome or exome. WGS and WES are increasingly being employed in the clinical setting in testing for both somatic mutations and germline variants. In addition, multigene tests are now available commercially or within an institution. Considerable debate surrounds the clinical, ethical, legal, and counseling aspects associated with NGS and gene panels. Future research is warranted to address these issues.
References
PDQ cancer genetics summaries focus on the genetics of specific cancers, inherited cancer syndromes, and the ethical, social, and psychological implications of cancer genetics knowledge. Sections on the genetics of specific cancers include syndrome-specific information on the risk implications of a family history of cancer, the prevalence and characteristics of cancer-predisposing variants, known modifiers of genetic risk, opportunities for genetic testing, outcomes of genetic counseling and testing, and interventions available for people with increased cancer risk resulting from an inherited predisposition.
The source of medical literature cited in PDQ cancer genetics summaries is peer-reviewed scientific publications, the quality and reliability of which is evaluated in terms of levels of evidence. Where relevant, the level of evidence is cited, or particular strengths of a study or limitations of the evidence are described.
Refer to the Levels of Evidence for Cancer Genetics Studies summary for more information on the levels of evidence utilized in the PDQ cancer genetics summaries.
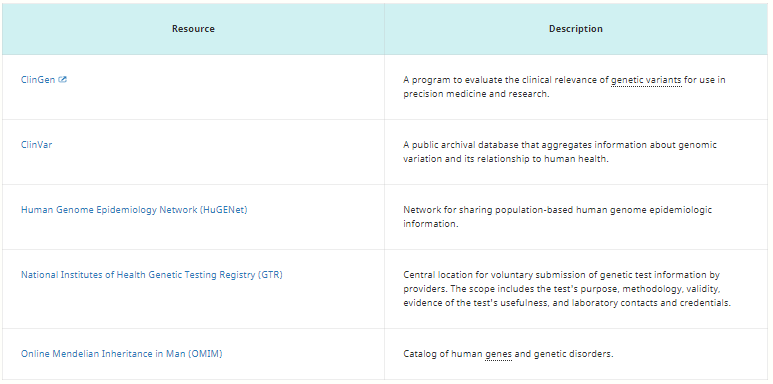
Health care providers who deliver genetic services, including genetic counseling, can be located through local, regional, and national professional genetics organizations such as the National Society of Genetic CounselorsExit Disclaimer. Providers of cancer genetic services are not limited to one specialty and include medical geneticists, genetic counselors, advanced practice genetics nurses, oncologists (medical, radiation, or surgical), other surgeons, internists, pediatricians, family practitioners, and mental health professionals. A cancer genetics health care provider will assist in constructing and evaluating a pedigree, eliciting and evaluating personal and family medical histories, and calculating and providing information about cancer risk and/or probability of a pathogenic variant being associated with cancer in the family. In addition, if a genetic test is available, these providers can assist in pretest counseling, laboratory selection, informed consent, test interpretation, posttest counseling, and follow-up.
The PDQ cancer information summaries are reviewed regularly and updated as new information becomes available. This section describes the latest changes made to this summary as of the date above.
Editorial changes were made to this summary.
This summary is written and maintained by the PDQ Cancer Genetics Editorial Board, which is editorially independent of NCI. The summary reflects an independent review of the literature and does not represent a policy statement of NCI or NIH. More information about summary policies and the role of the PDQ Editorial Boards in maintaining the PDQ summaries can be found on the About This PDQ Summary and PDQ® – NCI’s Comprehensive Cancer Database pages.
This PDQ cancer information summary for health professionals provides comprehensive, peer-reviewed, evidence-based information about cancer genetics. It is intended as a resource to inform and assist clinicians in the care of their patients. It does not provide formal guidelines or recommendations for making health care decisions.
This summary is reviewed regularly and updated as necessary by the PDQ Cancer Genetics Editorial Board, which is editorially independent of the National Cancer Institute (NCI). The summary reflects an independent review of the literature and does not represent a policy statement of NCI or the National Institutes of Health (NIH).
Board members review recently published articles each month to determine whether an article should:
Changes to the summaries are made through a consensus process in which Board members evaluate the strength of the evidence in the published articles and determine how the article should be included in the summary.
Any comments or questions about the summary content should be submitted to Cancer.gov through the NCI website’s Email Us. Do not contact the individual Board Members with questions or comments about the summaries. Board members will not respond to individual inquiries.
Some of the reference citations in this summary are accompanied by a level-of-evidence designation. These designations are intended to help readers assess the strength of the evidence supporting the use of specific interventions or approaches. The PDQ Cancer Genetics Editorial Board uses a formal evidence ranking system in developing its level-of-evidence designations.
PDQ is a registered trademark. Although the content of PDQ documents can be used freely as text, it cannot be identified as an NCI PDQ cancer information summary unless it is presented in its entirety and is regularly updated. However, an author would be permitted to write a sentence such as “NCI’s PDQ cancer information summary about breast cancer prevention states the risks succinctly: [include excerpt from the summary].”
The preferred citation for this PDQ summary is:
PDQ® Cancer Genetics Editorial Board. PDQ Cancer Genetics Overview. Bethesda, MD: National Cancer Institute. Updated <MM/DD/YYYY>. Available at: https://www.cancer.gov/about-cancer/causes-prevention/genetics/overview-pdq. Accessed <MM/DD/YYYY>. [PMID: 26389204]
Images in this summary are used with permission of the author(s), artist, and/or publisher for use within the PDQ summaries only. Permission to use images outside the context of PDQ information must be obtained from the owner(s) and cannot be granted by the National Cancer Institute. Information about using the illustrations in this summary, along with many other cancer-related images, is available in Visuals Online, a collection of over 2,000 scientific images.
Share this:
3517 Breakwater Ave
Hayward, CA 94545
© 2025 GeneVerify Inc.
